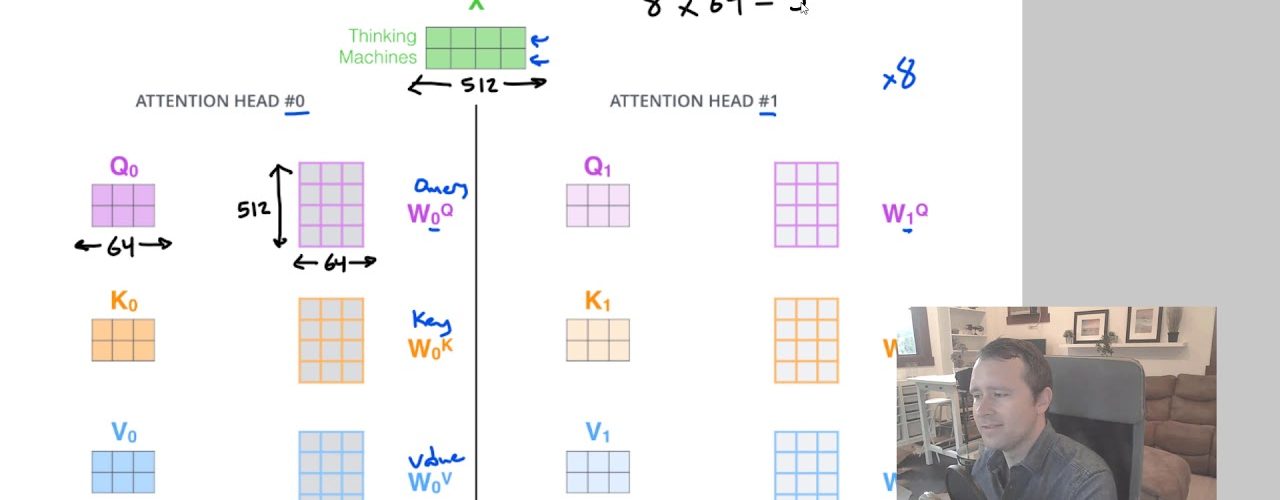
The “Self-Attention” mechanism that we learned about in Episode 5 is actually replicated multiple times in the Transformer architecture–this is referred to as “Multi-Headed Attention”. In this video we’ll dig into this in detail, and see how it impacts the compute the cost of the overall model.
We’ll again be relying heavily on the excellent illustrations in Jay Alammar’s post, “The Illustrated Transformer”: http://jalammar.github.io/illustrated-transformer/.
==== Full Series ====
The Bert Research Series is complete! All 8 Episodes are up:
https://www.youtube.com/playlist?list=PLam9sigHPGwOBuH4_4fr-XvDbe5uneaf6
==== Updates ====
Sign up to hear about new content across my blog and channel: https://www.chrismccormick.ai/subscribe


Add comment