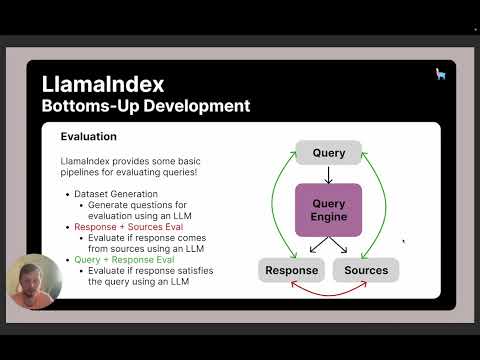
In part 3 of this series, we discuss the process of evaluating query engines using LlamaIndex. We explain how to customize LLMs and load documents, and then demonstrate how to assemble a baseline query engine easily. We highlight some challenges of evaluating uncontrolled outputs and runtime costs associated with LLMs and embeddings. We discuss how to measure hallucination by analyzing the response and sources. Additionally, we provide a step-by-step guide on setting up a query engine and evaluating its performance using GPT-4.
Our Bottoms Up Development series is designed to help you understand the low-level building blocks of LLM application development. It’s important to play around with the basic concepts before composing more complex LLM software systems – our end goal is to help you learn all the fundamental concepts to build a chatbot over our documentation.
Follow along on our Github repo: https://github.com/run-llama/llama_do…



Add comment