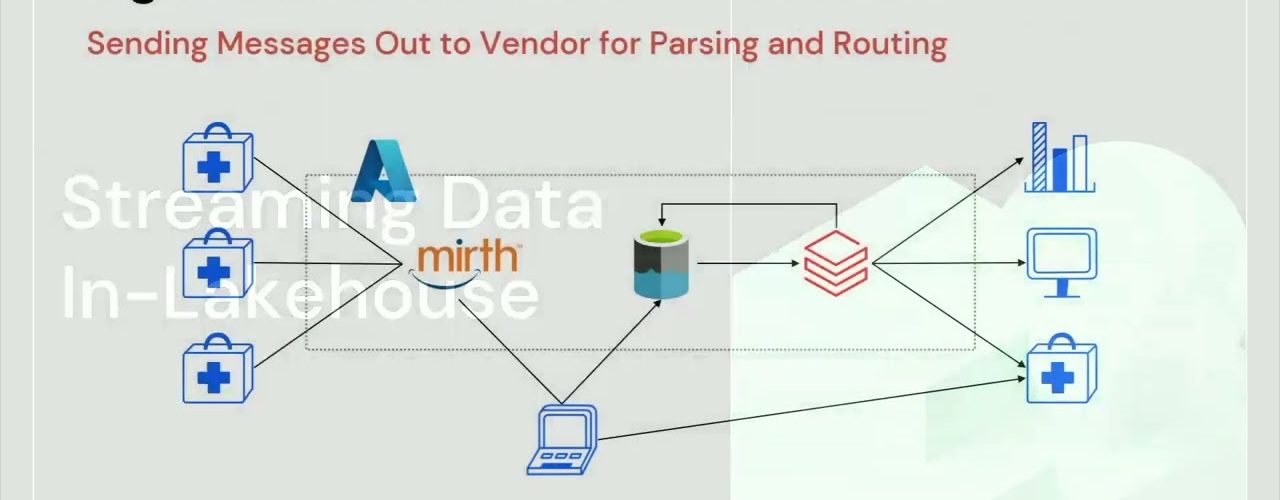
Chesapeake Regional Information System for our Patients (CRISP), a nonprofit healthcare information exchange (HIE), initially partnered with Slalom to build a Databricks data lakehouse architecture in response to the analytics demands of the COVID-19 pandemic, since then they have expanded the platform to additional use cases. Recently they have worked together to engineer streaming data pipelines to process healthcare messages, such as HL7, to help CRISP become vendor independent.
This session will focus on the improvements CRISP has made to their data lakehouse platform to support streaming use cases and the impact these changes have had for the organization. We will touch on using Databricks Auto Loader to efficiently ingest incoming files, ensuring data quality with Delta Live Tables, and sharing data internally with a SQL warehouse, as well as some of the work CRISP has done to parse and standardize HL7 messages from hundreds of sources. These efforts have allowed CRISP to stream over 4 million messages daily in near real-time with the scalability it needs to continue to onboard new healthcare providers so it can continue to facilitate care and improve health outcomes.
Talk by: Andy Hanks and Chris Mantz
Connect with us: Website: https://databricks.com
Twitter: https://twitter.com/databricks
LinkedIn: https://www.linkedin.com/company/databricks
Instagram: https://www.instagram.com/databricksinc
Facebook: https://www.facebook.com/databricksinc


Add comment