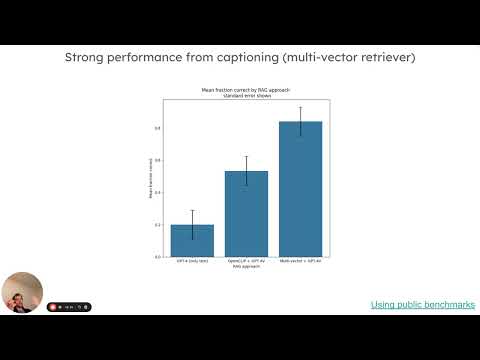
Visual assistants will be an important theme in 2024 as multi-modal LLMs gain wider adoption and capabilities. We’ve released 5 new templates as an entry points to GPT-4V, Gemini, and open source models. In this video, we provide some background on multi-modal LLMs, show results from our internal evaluations using LangSmith, highlight the trade-offs between architectures for multi-modal RAG, and introduce how to use these templates to get started.
Important Links
(1) Open source multi-modal LLMs for private visual search over your photos
https://templates.langchain.com/?integration_name=rag-multi-modal-local
https://templates.langchain.com/?integration_name=rag-multi-modal-mv-local
(2) GPT-4V or Gemini for visual RAG over slide decks
https://templates.langchain.com/?integration_name=rag-gemini-multi-modal
https://templates.langchain.com/?integration_name=rag-chroma-multi-modal
https://templates.langchain.com/?integration_name=rag-chroma-multi-modal-multi-vector
Slides
https://docs.google.com/presentation/d/19x0dvHGhbJOOUWqvPKrECPi1yI3makcoc-8tFLj9Sos/edit#slide=id.p


Add comment